[Released] Anilip3 [Commercial]
 Dobit
Posts: 202
Dobit
Posts: 202
We are pleased to announce the next generation of Anilip!
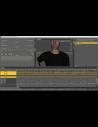
Anilip3 is a tool for automatic lip animation and synchronization.
Anilip3 has been completely redesigned.
It is now based on modern AI models for speech and viseme recognition.
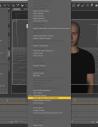
Anilip3 covers the main use cases for lip animation
- Text only for "silent" animations or subsequent synchronization.
- Speech recognition
- Text to Speech
The speech recognition is based on modern AI models and offers very good recognition rates even in poor recording conditions.
Anilip3 supports all Windows SAPI TTS voices and SAPI voices from external vendors.
With Anilip3, many new English and international neural voices are also offered in additional packages
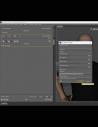
Anilip3 is now dialog based
Anilip3 is now dialogue based. Lip animation can be implemented for multiple speakers. This allows scenes to be designed like a script.
Dialogues can be reorganized independently of the timeline.
The audio recording is now saved for each dialogue entry and can be played back individually.
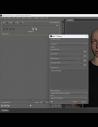
Interactive SSML Editor
An interactive SSML editor allows you to mark up speech attributes.
This allows you to insert pauses, adjust speech speed, pitch and emphasis (depending on the TTS voice used)
Anilip3 Bundle
Anilip3 has become a very powerful and comprehensive program.
We have therefore decided to split the program into components, which we also offer as a bundle.
Anilip3 Bundle consists of the followoing products:
- Anilip3 Main Program - supporting Genesis 9 and English language
- Anilip3 Figures Pack - supporting many other figures (mainly those of Anilip2)
- Anilip3 Language Pack - supporting many additional languages
- Anilip3 Neural Voices English - offering 18 additional neural voices
- Anilip3 Neural Voices International - offering 54 voices from 36 languages
Anilip3 is offered for Windows only.




Daz 3D is part of 
Connect
DAZ Productions, Inc.
7533 S Center View Ct #4664
West Jordan, UT 84084
Licensing Agreement | Terms of Service | Privacy Policy | EULA
© 2025 Daz Productions Inc. All Rights Reserved.
Comments
So does this require AI subscription, or is it usable on a standalone PC not connected to the internet?
All AI models are delivered with the Anilip3 products. The plugin requires a one-time activation. After that it works offline.
This looks to be great!
Usage rights of the generated voices? Can they be used commercially?
This has to be checked on a case-by-case basis. It depends on the source of the voices. Microsoft regulations apply to all Windows SAPI voices. Third-party providers of SAPI voices have their own terms of use. For the neural voices that we offer, we deliver .card files. Reference is made here to the usage rights. Many neural voices are in the "public domain", others are subject to special rights.
The ones that are included in the package (and the expansion ones) got clear labeling on which one is Public Domain and which isn't?
Last question: This works only with generated voices or can use real voiceovers recordings?
Hello! Will you please provide sample videos using the neural voices? Given the AI voice market, I'm curious to see where this product stands up. Thanks.
Yes, there is a clear labeling for each neural voice.
You can use voiceover recordings as well.
Thanks for the suggestion. We will make a demo for English voices.
Please make a demo using Filatoon, because of its instant rendering times.
Would be great to see, how it goes.
We use the Piper Engine as the basis for our voices. I just saw that they also have a demo page. Maybe that will help you get started. Many of the voices can be found in Anilip3.
Watching the promo I wasn't sure it this generates the sythensised voice sounds or if it just animates figures to look as if they are talking a seperatley generated soubndtrack. Doe this product include voice sounds?
Voice over is used in the promo video. Otherwise, Anilip3 offers a large selection of TTS voices. Windows SAPI and neural voices.
Well Just picked this up. Hopefull. Initial Exploration, found issues.
a) many items in your window need mouse over tool tips. Having to scour the manual to try and find out what each little icon means or does is cumbersome.
b) loading daz with one windows default/selected sound device. amd then changing that to another, (i.e. from speakers to headphones), as not everyone wants to listen. Anilip 3, does not switch to use the newly set sound device as per windows.
3. editing a created dialog I'm sure is helpful. With no option to change the used voice, means I have to delete, recreate the dialogue, for each and every voice to hear what they sound like until I find the one I want. Some sort of preview feature of each voice ("This is a test") with reference of where it can be found (i.e English Austrialina, specific name) would go a long way to speed up workflow, as opposed to users testing each one individually until the find the one they believe meets their concept.
Any work arounds, solutions, or features that resolve these issues, that I have not found or am not aware of, would greatly be appreciated.
And Hard DAZ crash after trying to play back the US Eng, Kathleen voice with <prosody pitch="x-high">This is a test.</prosody>
I think the Windows SAPI voices run locally on the PC but TTS voices need a connection to an online server, is this correct? And do the neural voices run locally or do they need a connection to a server?
All voices run locally.
Thank you for that clarification. it makes the package a lot more attractive (I don't trust cloud based stuff in the long term).
I haven't done any animations so far but Filament should make animation practical on my not very powerful computer and this looks really good.
Thank you for the feedback.
a) We actually made sure that all elements have tooltips and all dialogs also have interactive help so that you don't always have to look in the manual (see examples). However, there is always a small delay (1 second) before the tooltip appears. See screenshots.
b) This seems to be a problem. We will have a look.
c) The editing function is used to edit an existing entry. More precisely, to adjust the timing of the words. This only works with the underlying voice. For a different voice, the timing would be different.
To give an entry a different voice, please proceed as follows.
I like the idea of a preview. Perhaps we can improve the workflow here.
We're sorry. This shouldn't happen. We're looking into it.
I was going to ask if it is supported inder DS 4.21.0.5 but having just looked at the details I have to ask, instead (or as well?), is it supported under WIndows 7?
Windows 7 will not work. Requirement is Windows 11. DS 4.21. should work, but it has been tested on DS 4.22
I want to know this. I would rather not facilitate an online connection to use the product.
Does it have to be Windows 11? My computer is running Windows 10 and it can't run 11.
Ok, thanks - I suspected that was so.
Is this the result of accent injection.
Input:
ENG UK: Abigail
<prosody pitch="x-high">Hello. My name is Teemay. Not Timmy or Tim, but, Tee May.</prosody>
Output:
hey my name is team a not to me or tim but team a
The 'team a' portion does sound correct like the intended 'Teemay'. But when you get to the part that says 'not to me or tim but team a' It sounds like 'Not a mutant but team a'
Sorry the tags don't copy/paste either it seems.
Will i need to play with phonetics through spelling to get the intended pronounciation in some cases? Like the dreaded pheonix sounding like Puh-ho-nix and having to write it phonetically Fee nicks?
edit: Originally posted at 2:30pm EST not 8:20pm EST otherwise I would have combined the two posts into one rather than two seperate posts at the exact same minute,. - blackhole anomoly
I started this for my own reference, but felt I'd share. Here is an .xlxs file of all supported tags for English voices. I don't speak well enough in other languages to provide those. But if anyone cares to make one I'm sure others would welcome it.
Interesting note: It appears so far that ONLY MS voices support tags other than say-as.
Also if someone feels there is a better thread this should be contained in let someone know who can move it. I will be working on my own previews of each voice "This is a test." and exporting them as wavs. I may eventually upload the set for others.
At the moment, it is mainly SAPI voices that support extended SSML tags. Both from Microsoft and from third-party providers. Neural voices usually lack this support because they cannot be manipulated at either the phoneme level or the word level. AI models for speech synthesis are trained with example sentences and the synthesis can only generate complete sentences. They fail if you force them to reproduce sentences word by word. The models need a context. SAPI voices work at the phoneme level. SSML tags are not a problem here. We are still working on giving neural voices better SSML support, but do not yet have any productive solutions.
As we mentioned above, no online connection is required. All models work offline.
I have not be able to identify SAPI specific voices in order to suggest that a voice may be more compatible with SSML tags. Is there a way to do this within your api?
By coding/training it yourself, or relying on the voice models trainers/creators to do the work, and once they complete it, you can add/replace the freesource model with the updated one? If you are relying on the original trainers/creators, how many of them that you are using are still actively working/updating the models you use?